This is the final article in the series on looking at Inversion of Coupling Control (IoCC) composition. The previous articles covered:
This article looks at providing a mathematical model to explain the composition.
Just a little disclaimer that I'm not a mathematics boffin. I've a degree in computer science but it did not cover much functional programming. Much of this is through my self taught understanding of functional programming and mathematics. Therefore, I'm happy to take feedback from more capable mathematicians on better ways to express the model. However, I'm hoping this article reasonably conveys the underlying model for composition with Inversion of Coupling Control.
From Category Theory, we have the associative law:
f(x) . g(x) = f.g(x)
With this we can introduce dependencies:
f(x)(d1) . g(x)(d2) = f.g(x)(d1, d2)
where:
d is a set of dependencies
This makes the program very rigid, as changing d1 to d3 has significant impact for use of f(x)(d1 now d3). For example, switching from database connection to REST end point.
ZIO attempts to reduce the rigidity by the following:
f(x)(d1) . g(x)(d2) = f.g(x)(D)
where:
D = d1 + d2
Or, in other words:
D extends d1 with d2
Now, we can create lots of morphisms and at execution of resulting ZIO, provide a hom(D), which is the set of all required dependencies.
So, this model works. It is certainly enabling injection of dependencies in functional programs.
Now, I'd like to take another tact to the problem.
The
Imperative Functional Programming paper could not see how to remove the continuation type (z) from the signature. The authors did conclude Monads and CPS very similar, but due to the extra continuation type on the signature and the author's intuition, the IO Monad was the direction forward.
Now I certainly am not taking the tact to replace IO Monad with CPS. I'm looking to create a complementary model. A model where continuations decouple the IO Monads.
So introducing dependencies to the IO Monad, we get:
IO[x](d)
where:
d is the set of dependencies required
This then follows, that joining two IO together we get:
IO[x](d1, d2)
So, maybe let's keep the IO Monad's separate and join them via CPS. This changes the signature to:
IO[x](d)(z)
where:
z = Either[Throwable,x] -> ()
The pesky z that the Imperative Functional Programming paper was talking about.
However, discussed previously is
Continuation Injection. This effectively hides the z from the signature, making it an injected function. As it's an injected function, the z becomes an indirection to another function. This indirection can be represented as:
IO[_](d1) -> (Either[Throwable,y] -> IO[y](d2)) -> IO[y](d2)
Note: the joined IO need only handle y or any of it's super types. Hence, the relationship indicates the passed type. This makes it easy to inject in another IO for handling the continuation.
Now to start isolating the IO Monads from each other, we are going to start with
Thread Injection.
d -> Executor
This represents Thread Injection choosing the appropriate Executor from the dependencies. Therefore, we can then introduce a Thread Injection Monad to choose the Executor.
F[_](d)(Executor) -> (d -> Executor) -> TI[F[_](d)]
where
TI is the Thread Injection Monad that contains the dependency to Executor mapping to enable executing the IO Monad with the appropriate Executor.
This then has the above continuation between IO Monads relationship become.
TI[IO[_](d1)] -> (Either[Throwable,y] -> IO[y](d2)(Executor)) -> TI[IO[y](d2)]
Now the IO Monads can be executed by the appropriate Executor via the TI Monad.
Further to this, we can model dependency injection with:
F[_](d) -> (F[_](d) -> F[_]) -> DI[F[_]]
where
DI is the Dependency Injection Monad that supplies dependencies to the function.
Note that DI Monad will also manage the life-cycle of the dependencies. Discussion of how this is managed will be a topic for another article.
So the above IO Monad continuation relationship becomes:
TI[DI[IO[_]]] -> (Either[Throwable,y] -> IO[y](d)(Executor)) -> TI[DI[IO[y]]]
where:
DI propagates the same instances of dependencies across the continuation
Now, with Continuation Injection we are not limited to injecting in only one continuation. We can inject in many:
TI[DI[IO[_]]] -> (Either[Throwable,y] -> IO[y](d)(Executor)) -> TI[DI[IO[y]]]
-> (Either[Throwable,w] -> IO[w](d)(Executor)) -> TI[DI[IO[w]]]
...
Note: I'm guessing this can be represented on a single line (possible as set of continuations from a particular IO) but I'll leave that to a boffin more mathematical than me.
This means we can remove the Either and have the (possibly many) exceptions handled by separate continuations to get:
TI[DI[IO[_]]] -> (y -> IO[y](d)(Executor)) -> TI[DI[IO[y]]]
-> (ex -> IO[ex](d)(Executor)) -> TI[DI[IO[ex]]]
...
This demonstrates that an IO may now actually have more than one output. By having the ability to inject multiple continuations, the IO is capable of multiple outputs.
It is also execution safe.
OfficeFloor (Inversion of Coupling Control) ensures the handling of one continuation completes before the next continuation begins executing. This ensures only one IO is ever being executed at one time.
Further to this we can qualify DI. Originally we had d1, d2 that was hidden by DI. We can qualify the scope of DI as follows:
DI[P,T,_]
where:
P is the set of process dependency instances
T is the set of thread dependency instances
This allows for the following.
Same thread = DI[P,T,_] -> (_ -> _) -> DI[P,T,_]
Spawned thread = DI[P,T,_] -> (_ -> _) -> DI[P,S,_]
New process = DI[P,T,_] -> (_ -> _) -> DI[Q,S,_]
In other words,
- spawning a thread is creating a new set of thread dependencies instances
- interprocess communication is a different set of process dependency instances
Further to this:
- the set of T may only be the same if the set of P is same
- context (eg transactions) apply only to dependencies in T
The resulting IO Monad relationship for a same thread continuation becomes.
TI[DI[P,T,IO[_]]] -> (y -> IO[y](d)(Executor)) -> TI[DI[P,T,IO[y]]]
while a spawned thread continuation relationship is modelled as follows.
TI[DI[P,T,IO[_]]] -> (y -> IO[y](d)(Executor)) -> TI[DI[P,S,IO[y]]]
What this essentially allows is multi-threading concurrency. Any continuation may spawn a new thread by starting a new set of thread dependencies. Furthermore, OfficeFloor will asynchronously process the continuation returning control immediately. This has the effect of spawning a thread.
The same goes for spawning a new process.
TI[DI[P,T,IO[_]]] -> (y -> IO[y](d)(Executor)) -> TI[DI[Q,S,IO[y]]]
Therefore, with OfficeFloor, processes and threading are a configuration not a programming problem. Developers are no longer required to code thread safety into their possible imperative code within the IO. As the seldom used process dependencies are coded thread safe, this relationship introduces the ability for mutability within the IO that is thread safe. The isolation of dependencies prevents memory corruption (assuming dependencies respect not sharing static state).
OfficeFloor (Inversion of Coupling Control) is in this sense possibly the dark side. Functional programming strives for purity of functions being the light. Given OfficeFloor can handle:
- multiple outputs from IOs including exceptions as continuations
- mutability within the IOs that is thread safe
OfficeFloor enables modeling the darker impurities (or maybe I just watch too much StarWars).
What we now have is a possible "inversion" of the function:
- Function: strives to be pure, may have multiple inputs and only a single output.
- IoCC: allows impurities, has a single input and may have multiple outputs.
I personally like to think of functions like parts of a machine. They are highly coupled engine cogs providing always predictable output.
I then like to think of IoCC like signals. This is a more organic structure of loosely coupled events triggering other loosely coupled events. The result is a mostly predictable output. This is more similar to human decisioning outputs.
Regardless, we now have a typed model that can be represented as a directed graph of interactions. The IO Monads are the nodes with the various continuations edges between them. An edge in the graph is qualified as follows.
TI[DI[IO]] == y,p,t ==> TI[DI[IO]]
where:
y indicates the data type provided to the continuation
p indicates if a new process is spawned (represented as 0 for no and 1 for yes)
t indicates if a new thread is spawned (again represented as 0 for no and 1 for yes)
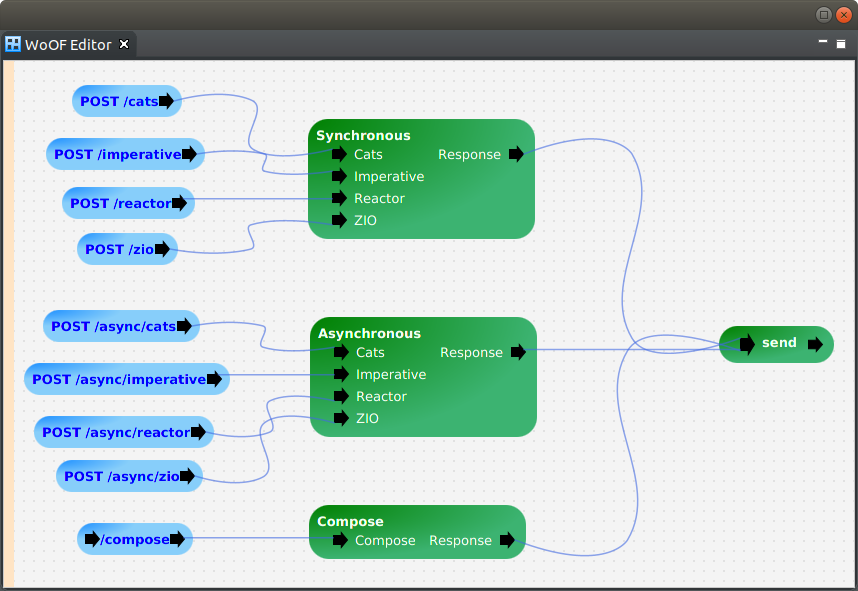
The result is the following example graph.
which, is essentially the OfficeFloor Continuation Injection configuration.
Summary
All of the above is already implemented in
OfficeFloor.
What this article has attempted to cover is the core underlying model. It has looked at how injected continuations can be used to join together IO instances. Further, it looked at the dependencies and how they can be used to model processes and threads.
Future Work
At the moment, we're focused on making building non-distributed applications a pleasure with OfficeFloor. This runs on the premise that if you are not enjoying building smaller applications with a toolset, why would you want to build larger more complex applications with that toolset.
However, we are nearing the completion of the bulk of this work.
We will be looking to simplify building distributed applications soon.
This will be achieved by looking at algorithms to examine the directed graph of continuations to decide on best places to separate the IOs into different containers. What the algorithms will take into account are the above relationships. In particular:
- the directed graph of continuations
- isolating sub graphs by the process (and possibly thread) dependency rules
- identifying which sub graphs to isolate to another container by incorporating run time metrics of the IOs
Note that we can model interprocess communication as:
Async (e.g. queue) = DI[P,T,_] -> (message -> _) -> DI[Q,S,_] -> ()
Sync (e.g. REST) = D[P,T,_] -> (request -> _) -> D[Q,S,_] -> (response -> _) -> D[P,T,_]
This can provide type safe modeling of distributing the IOs within the directed continuation graph.
Note that we may have to mark dependency instances that carry non-replicatable state between IO Monads. In other words, a database connection (not in transactional context) can be replicated by obtaining another database connection from the pool. However, a dependency that stores some value in it from one IO Monad that is used by the next IO Monad is non-replicable.
In practice, this has only been variable dependencies to further remove the parameter coupling between IO Monads (see
OfficeFloor tutorials).
However, we are also finding in practice that it is relatively intuitive to find sub graphs to isolate to their own containers. Endeavours in this work will likely look at automation of dynamically isolating sub graphs to containers as load changes (effectively having selective elastic scale of functions not arbitrarily bounded microservices).