
We use inversion of control and dependency injection and even push it as the correct way to build applications. Yet, we can not clearly articulate why!!!
The reason is we have not clearly identified what "control" is. Once we understand what we are inverting, the concept of Inversion of Control vs Dependency Injection is not actually the question to be asked. It actually becomes the following:
Inversion of Control = Dependency (state) Injection + Thread Injection + Continuation (function) Injection
To explain this, well, let's do some code. (And yes, the apparent problem of using code to explain Inversion of Control is repeating, but bear with me - the answer has always been right before your eyes).
One clear use of Inversion of Control / Dependency Injection is the repository pattern to avoid passing around a connection. Instead of the following:
public class NoDependencyInjectionRepository implements Repository<Entity> {
public void save(Entity entity, Connection connection) throws SQLException {
// Use connection to save entity to database
}
}
Dependency Injection allows the repository to be re-implemented as:
public class DependencyInjectionRepository implements Repository<Entity> {
@Inject Connection connection;
public void save(Entity entity) throws SQLException {
// Use injected connection to save entity to database
}
}
Now, do you see the problem it just solved?
If you are thinking, I can now change the Connection to say REST calls and this is all flexible to change. Well, you would be close.
To see the problem it solved, do not look at the implementation. Look at the interface. The client calling code has gone from:
repository.save(entity, connection);
to the following:
repository.save(entity);
We have removed the coupling of the client code to provide a connection on calling the method. By removing the coupling, we can substitute a different implementation of the repository (again, boring old news, but bear with me):
public class WebServiceRepository implements Repository<Entity> {
@Inject WebClient client;
public void save(Entity entity) {
// Use injected web client to save entity
}
}
With the client able to continue to call the method just the same:
repository.save(entity);
The client is unaware that the repository is now calling a micro-service to save the entity, rather than talking directly to a database. (Actually, the client is aware but we will come to that shortly.)
So taking this to an abstract level regarding the method:
R method(P1 p1, P2 p2) throws E1, E2
// with dependency injection becomes
@Inject P1 p1;
@Inject P2 p2;
R method() throws E1, E2
The coupling of the client to provide arguments to the method is removed by Dependency Injection.
Now, do you see the four other problems of coupling?
At this point, I warn you that you will never look at code the same again once I show you the coupling problems. This is the point in the Matrix where I ask you if you want to take the red or blue pill, because there is no going back once I show you how far down the rabbit hole this problem really is - say that refactoring is actually not necessary and there are issues in the fundamentals of modelling logic in computer science (ok, big statement but read on and I can't put it any other way).
So you chose the red pill.
Let's prepare you.
To identify the four extra coupling problems, let's look at the abstract method again:
@Inject P1 p1;
@Inject P2 p2;
R method() throws E1, E2
// and invoking it
try {
R result = object.method();
} catch (E1 | E2 ex) {
// handle exception
}
What is coupled by the client code?
- the return type
- the method name
- the handling of exceptions
- the thread provided to the method
- changing it's return type
- changing it's name
- throwing a new exception (in the above case of swapping to a micro-service repository, throwing a HTTP exception rather than a SQL exception)
- using a different thread (pool) to execute the method than the thread provided by the client call
This is likely the point you look at me like Neo does in the Matrix going "huh"? Let implementations define their method signatures? But isn't the whole OO principle about overriding and implementing abstract method signature definitions? And that's just chaos because how do I call the method if it's return type, name, exceptions, arguments keep changing as the implementation evolves?
Easy. You already know the patterns. You just have not seen them used together where their sum becomes a lot more powerful than their parts.
So let's walk through the five coupling points (return type, method name, arguments, exceptions, invoking thread) of the method and decouple them.
We have already seen Dependency Injection remove the argument coupling by the client, so one down.
Next let's tackle the method name.
Method Name Decoupling
Many languages, including Java with lambda's, are allowing/have functions as first class citizens of the language. By creating a function reference to a method, we no longer need to know the method name to invoke the method:Runnable f1 = () -> object.method();
// Client call now decoupled from method name
f1.run()
We can even now pass different implementation of the method around with Dependency Injection:
@Inject Runnable f1;
void clientCode() {
f1.run(); // to invoke the injected method
}
Ok, a bit of extra code for not much value. But again bear with me. We have decoupled the method's name from the caller.
Next let's tackle the exceptions from the method.
Method Exceptions Decoupling
By using the above technique of injecting functions, we inject functions to handle exceptions:Runnable f1 = () -> {
@Inject Consumer<E1> h1;
@Inject Consumer<E2> h2;
try {
object.method();
} catch (E1 e1) {
h1.accept(e1);
} catch (E2 e2) {
h2.accept(e2);
}
}
// Note: above is abstract pseudo code to identify the concept (and we will get to compiling code shortly)
Now exceptions are no longer the client caller's problem. Injected methods now handle the exceptions decoupling the caller from having to handle exceptions.
Next let's tackle the invoking thread.
Method's Invoking Thread Decoupling
By using an asynchronous function signature and injecting an Executor, we can decouple the thread invoking the implementing method from that provided by the caller:Runnable f1 = () -> {
@Inject Executor executor;
executor.execute(() -> {
object.method();
});
}
By injecting the appropriate Executor, we can have the implementing method invoked by any thread pool we require. To re-use the client's invoking thread we just use a synchronous Exectutor:
Executor synchronous = (runnable) -> runnable.run();
So now we can decouple thread to execute the implementing method from the calling code's thread.
But with no return value, how do we pass state (objects) between methods? Let's combine it all together with Dependency Injection.
Inversion of (Coupling) Control
Let's combine the above patterns together with Dependency Injection to get the ManagedFunction:public interface ManagedFunction {
void run();
}
public class ManagedFunctionImpl implements ManagedFunction {
@Inject P1 p1;
@Inject P2 p2;
@Inject ManagedFunction f1; // other method implementations to invoke
@Inject ManagedFunction f2;
@Inject Consumer<E1> h1;
@Inject Consumer<E2> h2;
@Inject Executor executor;
@Override
public void run() {
executor.execute(() -> {
try {
implementation(p1, p2, f1, f2);
} catch (E1 e1) {
h1.accept(e1);
} catch (E2 e2) {
h2.accept(e2);
});
}
private void implementation(
P1 p1, P2 p2,
ManagedFunction f1, ManagedFunction f2
) throws E1, E2 {
// use dependency inject objects p1, p2
// invoke other methods via f1, f2
// allow throwing exceptions E1, E2
}
}
Ok, there's a lot going on here but it's just the patterns above combined together. The client code is now completely decoupled from the method implementation, as it just runs:
@Inject ManagedFunction function;
public void clientCode() {
function.run();
}
The implementing method is now free to change without impacting the client calling code:
- there is no return type from methods (slight restriction always being void, however necessary for asynchronous code)
- the implementing method name may change, as it is wrapped by the ManagedFunction.run()
- parameters are no longer required by the ManagedFunction. These are Dependency Injected, allowing the implementing method to select which parameters (objects) it requires
- exceptions are handled by injected Consumers. The implementing method may now dictate what exceptions it throws, requiring only different Consumers injected. The client calling code is unaware that the implementing method may now be throwing a HTTPException instead of SQLException. Furthermore, Consumers can actually be implemented by ManagedFunctions injecting the Exception.
- the injection of the Executor allows the implementing method to dictate it's thread of execution by specifying the Executor to inject. This could result in re-using the client's calling thread or have the implementation run by a separate thread or thread pool
All five coupling points of the method by it's caller are now decoupled.
We have actually "Inverted Control of the Coupling". In other words, the client caller no longer dictates what the implementing method can be named, use as parameters, throw as exceptions, which thread to use, etc. Control of coupling is inverted so that the implementing method can dictate what it couples to by specifying it's required injection.
Furthermore, as there is no coupling by the caller there is no need to refactor code. The implementation changes and then configures in it's coupling (injection) to the rest of the system. Client calling code no longer needs to be refactored.
So in effect Dependency Injection only solved 1/5 of the method coupling problem. For something that is so successful for only solving 20% of the problem, it does show how much of a problem coupling of the method really is.
OfficeFloor
Implementing the above patterns would create more code than it's worth in your systems. That's why the OfficeFloor (http://officefloor.net) "true" inversion of control framework has been put together to lessen the burdon of this code. This has been an experiment in the above concepts to see if real systems are easier to build and maintain with "true" inversion of control. Try the tutorials out to see the concepts in action (http://officefloor.net/tutorials). We value your feedback, as we ourselves feel so claustrophobic with the coupling imposed by the method signature.OfficeFloor is also an implementation of many other innovative patterns that is going to take many more articles to cover. However, the concepts have been published should you like some heavy academic reading (http://doi.acm.org/10.1145/2739011.2739013 with free download available from http://www.officefloor.net/about.html).
Possibly the most interesting aspect of these patterns is that the configuration is no longer in code, but actually done graphically. The follow is an example of this configuration:
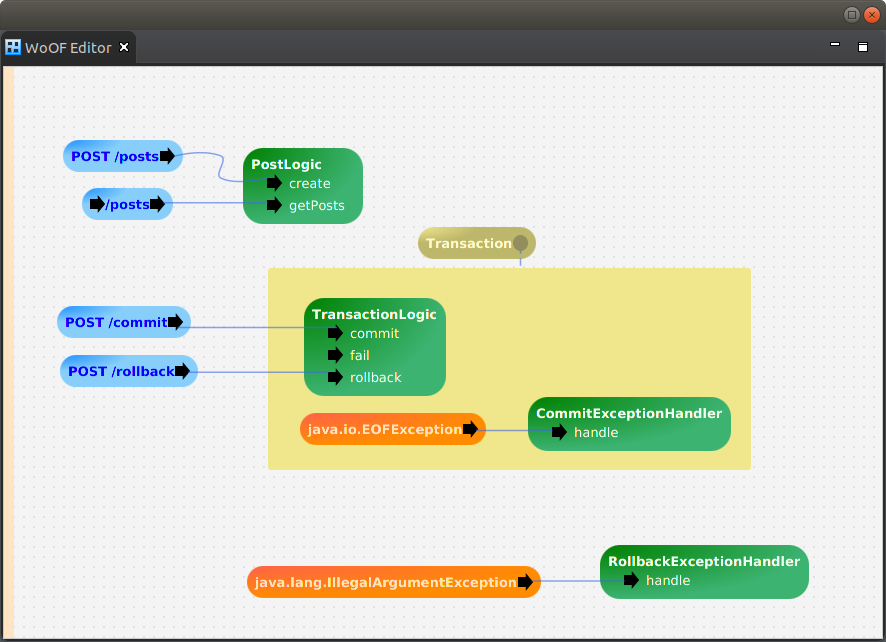
Summary
So next time you reach for the Refactor Button/Command, realise that this is brought on by coupling of the method that has been staring us in the face every time we write code.And really why do we have the method signature? It is because of the thread stack. We need to load memory onto a thread stack, and the method signature follows this behaviour of the computer. However, in the real world modelling of behaviour between objects there is no thread stack. Objects are loosely coupled with very small touch points - not the five coupling aspects imposed by the method.
Furthermore, in computing we strive towards low coupling and high cohesion. One might possibly put forward a case that in comparison to ManagedFunctions, that methods are:
- high coupling: as methods have five aspects of coupling to the client calling code
- low cohesion: as the handling of exceptions and return types from methods starts blurring the responsibility of the methods over time. Continuous change and shortcuts can quickly degrade the cohesiveness of the implementation of the method to start handling logic beyond it's responsibility
So given, as a discipline we strive for low coupling and high cohesion, our most fundamental building block (the method and also for that matter the function) may actually go against our most core principles.
I love this article. What a great read. Thanks for sharing Daniel.
ReplyDeletedamn man, you just laid out what I have been wrestling with for 20 years... i feel kinda "floored" lol. the ignored 80% of coupling "layers" on the problems we deal with on a daily basis. it totally is a red/blue pill kind of realization. I forked it and will grok what I can, be prepared for stupid questions. :0)
ReplyDeleteNo worries Mike. Happy others are starting to see the OO Matrix for what it is :) Always open to assisting :)
DeleteWhat is the OO Matrix? https://sagenschneider.blogspot.com/2019/08/what-is-oo-matrix.html
DeleteI'm a simple developer and to me this looks rather complex. I do understand what you are trying to convey. Do reactive libraries, like RXJava, try to solve the same problem (at least partially)? I have not yet had a look at your OfficeFloor solution, but I definitely will. I'm curious how you tackled these couplings.
ReplyDeleteTo my understanding, RXJava follow functional programming in using Monads (and the like) for composition (coupling logic together). This is all founded on top of the function. The function suffers the same coupling as the method.
DeleteOne thing RXJava typical indicates is that you must go fully Reactive. Basically, you can only write your app in Reactive or synchronous Servlet. Mixing requires you to understand each deeply (in particular the threading models) to make them work together.
Or use the the above concepts and check out https://sagenschneider.blogspot.com/2019/04/oo-functional-imperative-reactive.html
If you're coding against abstraction (interface) instead of implementation (class) AND you separated your layers, then you can achieve same results as described on top. No need for all this "unusual" code.
ReplyDeleteThe interface is the coupling I'm talking about.
DeleteThe most simple example is synchronous methods:
Result doSomething()
Now what happens if I want to make an asynchronous call within doSomething()? Without blocking the main thread (which is inefficient), I have to start refactoring the coupling of the interface to be a callback for the Result.
This is just one example. What if I want to change down stream flow calls. What if I require to call REST API end points through different exceptions to DB calls. It would all change the interface.
All of the above is "coupling" that you get from abstraction (template method interfaces). Separation of layers only makes this problem worse, as the layers enforce even more rigid coupling. For example, you have synchronous methods all the way down your layers, but now want to take advantage of asynchronous DB drivers? Refactoring the synchronous method coupling is a "huge" undertaking - potentially even a full rewrite.
With the above Inversion of Coupling Control, you just swap the calling code method out and you're done. Lot less coupling leading to lot less refactoring.
I actually find it "unusual" that for all the attempts of loosely coupled architectures, we still use tightly coupled methods. Very "unusual" :p